
Come fare un disastro senza rendersene conto
I metodi d’integrazione numerica sono quelli che permettono il calcolo degli integrali definiti di una funziona usando i calcolatori elettronici. Detto in maniera più accessibile (anche se non del tutto formalmente corretta), l’integrazione numerica è quel processo che conduce alla valutazione, in molti casi approssimata, dell’area compresa tra una curva di equazione y=f(x) e l’asse delle ascisse, in una regione x∈[a,b].

Uno dei metodi d’integrazione numerica più semplici e allo stesso tempo più usati, risale al tempo di Isaac Newton (a dimostrazione che il calcolo numerico non è affatto, come si crede, strettamente legato all’uso dei computer). Consiste nel dividere l’intervallo [a,b] in una serie di N intervalli più piccoli [xᵢ,xᵢ₊₁], con x₁=a e xN+1=b, approssimare f(x) in ciascuno di essi con un una costante f(x)≃f(xᵢ)=cost, e approssimare l’area sotto la curva come la somma delle aree di rettangoli di base xᵢ₊₁-xᵢ e altezza f(x̅), dove x̅ è il punto medio del sotto-intervallo [xᵢ,xᵢ₊₁].

In effetti, il simbolo d’integrale (∫ ) è una “esse” allungata che deriva dal latino summa (somma). Gli estremi d’integrazione a e b si indicano in basso e in alto. Quello che si somma, in un integrale, è il prodotto della base infinitesima dx di un rettangolo per la sua altezza f(x). La notazione, in sostanza, indica la somma delle aree dei rettangoli di altezza f(x) e larghezza infinitesima dx. In certi casi, l’integrale di alcune funzioni si sa calcolare esattamente. Chi ha studiato un po’ di analisi matematica sa, per esempio, che
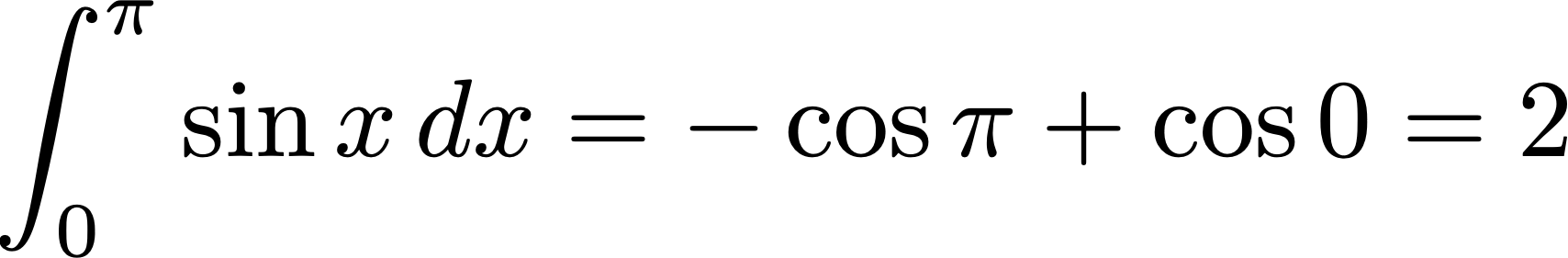
Numericamente, con un programma in C, l’integrale in questione si potrebbe calcolare come segue
double integral(double a, double b, int N) {
double I = 0., x = a;
double dx = (b - a)/N;
while (x < b) {
I += sin(x+0.5*dx)*dx;
x += dx;
}
return I;
}
In questa funzione si pone, inizialmente, la variabile I, che rappresenta l’integrale, uguale a 0. La variabile x, invece, si pone uguale ad a. Si divide quindi l’intervallo [a,b] in N parti di ampiezza dx. Nel ciclo while, alla variabile I si somma, iterativamente, il valore del seno di x, calcolato nel punto medio dell’intervallo, moltiplicato per dx, con x che si sposta ogni volta verso destra. Quando x finisce fuori dell’intervallo [a,b] la variabile I contiene la somma delle aree dei rettangoli di base dx e di altezza uguale al seno dei punti di mezzo di ciascun sotto-intervallo, che fornisce una stima dell’integrale. Una misura della precisione di questa stima è data da 𝛿=|2-I|/2, che fornisce la differenza percentuale tra il valore atteso 2 e quello stimato I.
La seguente tabella riporta il valore di 𝛿 per diversi valori di N.
| N | 𝛿 | N | 𝛿 |
|---|---|---|---|
| 1 | 57% | 8 | 0.6% |
| 2 | 11% | 9 | 0.5% |
| 3 | 4.7% | 10 | 0.4% |
| 4 | 2.6% | 11 | 1.7% |
| 5 | 1.7% | 12 | 0.3% |
| 6 | 5.6% | 13 | 1.2% |
| 7 | 0.8% | 14 | 0.2% |
N=1 equivale ad approssimare l’area sotto la funzione seno con quella di un rettangolo di base π e altezza uguale al seno di π/2, che vale 1. L’area così stimata (π) è chiaramente ben diversa da quella vera che vale 2. E infatti l’errore è grande (57%). All’aumentare di N, l’errore, come ci si potrebbe aspettare, diminuisce. Tuttavia, per certi valori di N, come N=6, N=11 e N=13, tale errore non solo non segue l’andamento decrescente atteso, ma è superiore di un ordine di grandezza rispetto a quello di valori del tutto simili dello stesso parametro.
In un recente post spiegavo come la scelta del costrutto da utilizzare per realizzare un ciclo dovesse basarsi sul tipo di controllo che si poteva eseguire: nel caso in cui si possa prevedere il numero di volte che il ciclo sarà percorso è più opportuno usare il costrutto for, riservando il while per le situazioni nelle quali questo non è possibile.
Nel caso in esame, seguendo quel consiglio, avremmo dovuto usare il for per realizzare il ciclo, così:
double integral(double a, double b, int N) {
double I = 0., x = a;
double dx = (b - a) /N;
for (int i = 0; i < N; i++) {
I += sin(x+0.5*dx)*dx;
x += dx;
}
return I;
}
In questo caso, i risultati che si ottengono sono esattamente gli stessi, ma per N=6, 11 e 13, gli errori corrispondenti sono, rispettivamente, 𝛿=1.1%, 0.3% e 0.2%, perfettamente in linea con le attese.
Come si spiega? Il fatto è che i numeri nella memoria di un calcolatore sono rappresentati sempre con un numero finito di cifre. Quando si somma dx a x può dunque accadere che, all’ultima iterazione, il valore risultante sia appena più piccolo o appena più grande di b, causando l’omissione o la ripetizione di un addendo nella somma. È così che, anche se l’errore su x, come nel caso in esame, è dell’ordine di 2-53, l’errore finale può essere disastrosamente alto. Usando il costrutto for garantiamo che il numero di intervalli effettivamente usati per la stima sia quello giusto.
Come si vede, l’adesione alle convenzioni descritte nel post sopra indicato, non è solamene una questione di stile, ma permette di limitare errori altrimenti difficili da controllare nei casi generali. Questo caso, inoltre, suggerisce un’ulteriore “regola“: quando si deve scegliere un numero intero arbitrario (come nel caso del numero di intervalli in cui dividere [a,b]), meglio scegliere una potenza di 2 (non 10, ma 8 o 16; non 100, ma 64 o 128; non 1000, ma 1024). Con quelle, gli errori di arrotondamento sono ridotti al minimo possibile.
Questo e altri suggerimenti dello stesso tenore sono contenuti nel mio libro “Programmazione Scientifica“, edito da Pearson.
